I’ve been applying to jobs for a few months now and I’m beginning to wonder whether AI has eaten them all. Not only the jobs but the companies I’m applying to as well. Being reasonably-well organised, I started keeping track of my applications and their states from day one. I should have used the CRM I wrote back in the 2000s but I needed more immediacy in the data entry and access (todo: feature request) so I used Google Sheets.
It became clear to me very quickly that a large proportion of these roles had something wrong with them – either basic details missing, usually no salary specified, or simply nobody on the other end of the application. I’m used to HR teams and processes being pretty crap most of the time, but this seems to be something else – no responses to direct applications, no responses to agency applications, duplicate vacancies clearly being reposted on LinkedIn within days of the original – what gives?
My go-to in these days of modern AI-enlightenment is that the role, the company, the candidate tracking system, or all of the above have probably been eaten by AI, but to what end? Simply harvesting details seems like a glorious waste of time, and from my many years of being on the receiving end of thousands of applications (and hiring lots of developers), the quality of a reasonable chunk of those rejected applications wouldn’t be good enough to use for model training unless you’re demonstrating what not to do.
Anyway, as my list of failed applications nears one hundred (since Feb 2025), I find myself with a reasonably complete, therefore reasonably decent quality dataset, albeit one with questionable utility, to screw about with in D3. Go play with it here because wordpress is a bit naff at embedding nice-sized iframes.
It used to be tidier, honest. NTP server, PDU, patch panel, UDM Pro, PoE switch, proxmox servers, fans, NAS, AI PC and shonky cooling. UPS not pictured. The small yellow boxes are wideband RF preamps.
So… I’m a geek. No hiding from it. Gone are the days when being a geek mostly meant having the shit beaten out of you in the playground. These days geeks rule the world. So, I’m a geek. I love playing with computers. I love playing with radio. I love playing with electronics. I’m a hacker, in the original sense of the word. That is to say I derive enjoyment from making tools, products, systems do things they weren’t designed to do.
Why? It’s educational, it’s fun, it’s frustrating enough to (sometimes, not always) give a great sense of satisfaction and achievement after solving a problem which has been bugging me for sometimes weeks. It’s inspiring, to learn new tools, to figure out what they’re good at, and what they’re bad at, and to use them to solve problems, more often than not, of my own making.
So I run a VPS (using Linode). I’ve run that VPS since 2008, running every Ubuntu release from 8.04 to 24.04. There I host my own MTA, my own web server for multiple domains, I host websites, databases, dev environments and access endpoints for other people – it’s very handy – and at home I run a homelab.
What’s a homelab? It’s intended for experimentation and learning systems, tools, applications, configurations and all that. All things you can and should learn on your day job, but without the knowledge from first-principles you’ll unlikely find that job int he first place.
Well perhaps my setup isn’t quite a homelab. A large proportion isn’t particularly experimental. A lot of the services I run at home keep me cosplaying as a sysadmin, that’s for sure. If you’re going to do it, you have to do it properly, so here goes:
Other devices on the network which aren’t directly in the homelab include things like a trusty DS1819+ Synology, HD Homerun, hamclock, Pi-Star, Echolink node, Allstarlink node, experimental Packet node, NTP server, enviro RPi Pico monitors and a raintrackr, not to mention the family laptops, PCs, TVs, iPads, smartphones, smart plugs, smart lights, NVR cameras, Echos, Google Homes and all that other junk.
Mostly kept online by an old Dell UPS cast-off from work – PoE Wireless APs to the rescue!
I’m sure I’ve forgotten a bunch of things, but that’s the gist of it. I do not like paying for subscription services if I can avoid it. I’m sure my response of installing everything and running it at home is pretty atypical, but I like being (mostly) in control of my own services.
The experimental side of my homelab actually comes in a different form – that’s the portable kit I take to field events (scouting and similar). That comes with a whole other set of hardware for servicing a mobile LAN but still having local fast file storage, server redundancy, backhaul links, VPN, caching, DNS and similar. That’s for another post.
There was a time when I would have STRONGLY preferred hiring developers and engineers into my teams who do this sort of stuff in their spare time. I’ve interviewed and hired a lot of developers and engineers into my teams over the last quarter century and I often look for the tinkerer in the candidate. I want them to be excited not only about the company or team but about technology itself.
To be honest I still think like that, apparently because I’m some sort of tech dinosaur. It seems learning and experimentation in one’s spare time has fallen out of fashion for a huge proportion of people. I don’t expect to see a stupid amount of github commit history – though that’s often encouraging to see. I know that if you’re working for most companies, that intellectual property is private, commercial, top secret, verboten, and certainly isn’t going on a public repository for a someone else’s AI training.
I get it – I was never paid for solving massive, difficult, long-standing system engineering and architecture problems for work in my sleep, which happened on many occasions, as might be expected when working on groundbreaking novel science. It certainly used to piss me off that what little recognition was received was never really proportional to the amount of effort put in either in work, or in overtime, or in own-time. I need to get over that – that’s a very much a “me” problem. In the meantime I need a bigger server cab.
What should I run on my homelab? What do you run on yours?
I’ve been excited by e-ink displays for a long while. I leapt on the original, gorgeous reMarkable tablet as soon as it came out and have been a regular user and advocate ever since. I would dearly love to have one or two of theseenormous 42″ e-ink art poster displays on the wall, but that’s for another day.
I’ve also been a long-time customer of Pimoroni and was aware of their range of nifty Inky displays. I recently came across this neat project by @mimireyburn and managed to pick up a 7.3″ Inky Impression after it being on back-order for only a week or two.
The Inky Impression 7.3″ with protective film and screen reflectionThe Inky Impression 7.3″ rear with mounted Raspberry Pi Zero 2W
After flashing RPi OS on a clean card for the Pi Zero 2W, downloading the project, setting up Python, compilers, virtualenvs, prerequisites, etc. I was presented with a complete failure of the underlying driver and inky library to communicate with the display. This isn’t a fault of the inky-calendar project at all, may I reiterate, but unfortunately a very regular occurrence I’ve found when using many Pimoroni products.
Searching around I tried a few different things, including the usual modifications to boot parameters to enable the drivers/kernel modules and fiddling with permissions, users etc. but with no success. Now I’ve never deliberately pretended to be a Python programmer, nor do I particularly wish to be one, but I’m pretty good with debugging weird stuff and this was definitely presenting as a driver/library issue. Specifically some of the differences with the Inky Impression 7.3 seemed to be tripping things up, and it wasn’t a hole I fancied spelunking in today.
A little more digging highlighted a NodeJS package by @aeroniemi with working Impression 7.3″ display support. I definitely have masqueraded as a JavaScript programmer in the past so things were looking up. Some light Claude.AI vibing and I had two working scripts – one to fetch images from PicSum and another to replicate the calendar fetching+rendering, both from public iCal and authenticated Google Cal sources – awesome!
Some dremel butchery on the back panel of an old 7″ picture frame to fit around the sticky-out components on the back of the board and I was in business.
The rear of the photo frame with cut-outs for most of the components on the rear of the displayExtra clearance given to the left-most microUSB power socket on the Pi Zero 2W
Improvements
The only slight drawback with using this NodeJS library is that it only handles the image-display side of things – there’s no built-in support for the function buttons – something to revisit another day.
Another improvement would be to better-handle power – the main benefit of e-ink is that it doesn’t need power once the display has been set, and that’s not being utilised here at all – there’s a cronjob running on the Pi which displays the calendar before 10:00AM and photos after that, refreshing every half-hour.
*/30 6-10 * * * cd /home/frame/ ; node ical2png.js --calendar x --calendar y --google-calendar z --service-account KEY.json --view week ; node main.js --image calendar.png
*/30 10-23 * * * cd /home/frame/ ; node main.js --dither
Lastly, obviously, the display needs to load images from a folder rather than from the internet. That’s super-quick to do, and that’s this afternoon’s job. The calendar-rendering – fonts, sizes, colours etc. could do with a little more spit and polish too.
In previous episodes of the Atari 520STFM refurbishment it was cleaned and recapped. This instalment sees installation of a replacement floppy drive. The GOTEK, sometimes known as FlashFloppy (really the name of the firmware it runs) is a drop-in replacement for a 3.5″ floppy disk drive which has several benefits:
It takes a FAT-formatted USB stick
The computer sees it as a normal floppy drive
It can serve a lot of 720K or 1.44MB disk images from a 16GB memory stick
A tiny OLED screen makes disk selection pretty easy
It’s much faster than a floppy drive
The downsides are that you can no longer use your old floppy disks, and sadly it doesn’t make those nostalgia-inducing head-seek noises… at least my one doesn’t!
There are a couple of different GOTEK models, one old and one newer. The story goes that the price of the disk controller 10x’d so the makers changed it and the firmware wasn’t immediately compatible. My one, bought on fleabay UK, May 2024 has the newer chip.
ARTERY AT32F415 GOTEK disk controller
The drive chassis is approximately the same size as the floppy drive being removed, but this one was found to be fractionally shorter (approx 1cm) so the power cable would not reach.
Power cable fails to reach even at full-stretch
This was resolved by cutting approxiamtely 6cm of floppy power cable from a dead ATX power supply, and soldering four spare header pins left over from an ESP32 project.
A salvaged floppy power connector extension
Naturally shrink-wrap sleeving is never available to hand so some fine purple electrical tape had to do. Hot glue would probably work quite well to secure the header pins as well.
Next come the flyleads for the GOTEK’s rotary controller and OLED display. Not all GOTEKs come with an external control/display – most seem to have the display built in and many only have up/down buttons, not a rotary control at all. Given the drive is on the side of the STFM, the standard display isn’t visible most of the time which isn’t very practical, so the external module seems much more useful. The display needs careful positioning as redoing it later is a PITA.
A small knife was used to very gently pry open one of the slots in the top of the case in order to position the display properly when clipped in. This is necessary because the connector blocks don’t fit through the slot without a little extra encouragement.
Gentle encouragement. Don’t crack the case!
I took a moment to appreciate the colour-coding on the wires and the fact that the connectors on duplicate colours are alternately polarised meaning they cannot be connected incorrectly. That’s super helpful, but countered by the fact these one-pin blocks don’t make very solid mechanical contact, tending to fall out if you look at them wrong. Securing them using small spots of superglue seems to help.
Flyleads superglued into place
The excess wires are pushed through from the above and the controller/display module is positioned and clipped onto the top of the ST case such that the wires can’t be seen.
Rotary Controller and OLED breakout module
The drive itself has the USB socket very close to the old eject button surround moulding which interferes very slightly but in practice it doesn’t seem to affect USB connectivity. Unfortunately in this configuration, in order to allow the ribbon cable to reach, the drive is technically mounted upside-down.
Mounted GOTEK drive
With everything closed back up it’s quite a smart-looking solution. Pretending to be a floppy drive doesn’t remove the quirks of using floppy disks but it does make them easier to deal with.
Atari 520STFM pictured with Ultrasatan SD virtual hard disk and GOTEK virtual floppy drive
The firmware version shipped on the drive seems fine but it’s possible to flash updates using the FlashFloppy code and documentation here. All in all the GOTEK is pretty easy to fit aside from the extra power extension. I will almost certainly be fitting more in the future.
In part three of my ongoing nostalgiathon refurbishing an Atari STFM it’s time to clean up the keyboard and case.
The keyboard assembly before cleaning
Step one is to remove the keyboard from the chassis – very simple to remove the seven short screws from underneath to release the top-side of the case. The keyboard floats on the shielding and is connected via a delicate 8 pin (7 wired and one polarising blank) header connector. This keyboard wasn’t very grubby – I’ve definitely seen much worse. A little grime and some letraset lower case, plus the usual dust, fluff and crumbs in-between the keys.
Detail of using a keycap puller
Using a keycap puller makes very quick work of removing all the key caps without damaging the switches or support pillars. The Enter and Space keys also have metal stabilisation bars which can be carefully unclipped from the keyboard chassis. Be gentle with these bars – they’re attached to the keycaps using small plastic clips which are easy to bend and break.
Alphabet soup: keycaps taking a bath
All the keycaps soaked in warm water and washing up liquid. These were individually scrubbed with a soft washing up pad, which was enough to remove the grime and the letraset.
The keyboard assembly with all keycaps removed
The keyboard chassis with included light muck. This was wiped first with surface cleaning disinfectant wipes then with cotton-buds and isopropyl alcohol (IPA).
Rinsing the keycaps
After scrubbing, the water was changed and the key caps were rinsed.
Stabilisation bars and keycaps drying
Keycaps were left to dry on kitchen towel. Also visible are the stabilisation bars for Enter and Space on the left, and one of the stabilisation support clips on the bottom.
Oxicleaned top case
Whilst the key caps were being cleaned, advantage was taken of a pleasant sunny afternoon. The top case was liberally sprayed with oxyclean peroxide spray (similar to Retrobright) and left in the sun for several hours, respraying and rotating every half hour or so. This can also be wrapped in clingfilm to reduce or avoid respraying.
Reassembled keyboard – looking clean!
All the keycaps were replaced using a reference photo taken before disassembly. The stabiliser pivots also had a pinhead of lithium grease applied. I imagine this is only really to reduce squeaking.
Reassembled STFM
Seeing everything reassembled in the case is very satisfying. The top case only suffered slight yellowing which has mostly cleared up now. I’ll have to try it again soon with my other STFM which is much worse.
In the unlikely event you read my earlier post on recapping the Atari STFM power supply, you’ll know I recently acquired a good example of a mid-late revision Atari 520STFM. Now its PSU has been recapped and cleaned up, it’s time to have a crack at upgrading it from half a megabyte of RAM to 4MB, the most it can take in stock config.
There are several ways to perform this upgrade, from the difficult but reliable desolder all the current RAM chips, source and buy new compatible ones and resolder them, to piggybacking daughterboards of various types, heavily dependent on the motherboard revision in question.
C103253 rev.1 Atari STFM motherboard before expansion
My motherboard is a C103253 rev.1, as pictured so for this upgrade I opted for the Exxos “The LaST Upgrade” MMU piggyback with a stacking board which sits on the shifter chip and connects with a ribbon cable.
Opening up the shielding (centre of image above) revealed a socketed shifter. Apparently this isn’t always the case but it’ll do for me. The shifter chip can be gently pried out of its socket with a thin blade, then inserted into the shifter daughterboard, which I bought fully assembled. This can then be inserted back into the shifter socket, and that part is complete. Next time I do this I’ll consider buying the kit to construct, as it’s not a very complicated assembly.
The shielding doesn’t fit back over the stacked shifter now, which is flagged as an outcome in the documentation. I didn’t want to completely remove the shielding so I opted to bend it over backwards over the video modulator. It just fits now under the main case shielding when it goes back on, which is great, but it does now interfere with the floppy ribbon cable in particular. This makes it awkward to put the original floppy drive back in but might be sufficient with a GoTek as they look a little shorter than the original drive. I don’t have one to test-fit yet so I might need to revisit this shield later.
Next on to the MMU piggyback. The pitch of these pins is smaller and they look very delicate compared to the pins on the shifter for example. This daughterboard sits directly on top of the MMU – its retaining clip needs to be removed – and requires a disconcerting amount of pressure to seat it fully in the socket, as its pins are jammed in next to the socket pins. I chose to pull the motherboard out of the bottom case, seat the daughterboard and carefully push down onto it, and a desk using the palm of my hand and my weight. It felt extremely uncomfortable as I’ve never had to use that much force to seat a chip.
Lastly the old RAM still soldered onto the motherboard either needs to be removed, or disconnected. Doing the latter is much less work and can be reversed later if necessary. The 68ohm resistors R59, R60 and R61 need lifting to 5V. On this motherboard this means desoldering and pulling the right-hand-side legs, closest to the MMU then adding a jumper wire over to the +ve leg of the 4700µF capacitor adjacent on the motherboard.
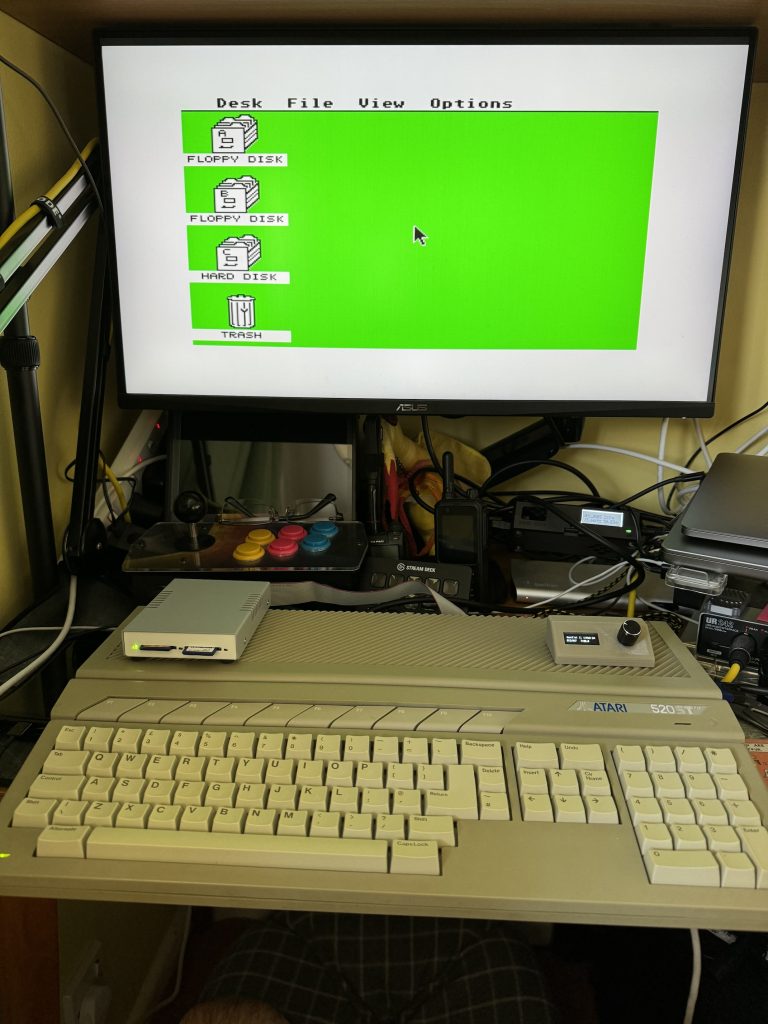
Use solid core wire, not like I did here4MB Atari STFM booted to GEM desktop
The result is a 4MB STFM (woowoo!) which boots to desktop and as yet has no way to run software because the flopy drive is dead and I haven’t formatted any SD cards for the ultrasatan yet (and will that even work with TOS 1.02?). Haha.
I recently acquired a classic 16bit machine from my childhood in the form of a Motorola 68000-powered Atari 520STFM. Whilst it’s a later motherboard revision – C103253 REV.1 – it’s still a low-spec model with only 512MB RAM. The “F” in STFM is for the included 3.5″ floppy disk drive with the “M” being for the built-in TV modulator.
My hope is to upgrade this machine to the maximum of 4MB RAM and see which other add-ons (e.g. GoTek USB-stick floppy drive replacement; ultrasatan SD-card virtual hard drive; TOS upgrades; PiStorm accelerator) will best modernise the experience.
Atari 520STFM motherboard C103253 Rev.1
But first things first, I know enough to not turn it on in excitement – the most common fault with these older machines is failing electrolytic capacitors as the paste in them dries out, particularly in hotter environments like power supplies, so let’s have a look at the PSU… This model is a common Mitsumi SR98. We’re looking for bulging capacitor packages like this one.
A bulging electrolytic capacitor
The Exxos PSU refurbishment kit includes a replacement set of capacitors, a couple of replacement resistors and modern, more-efficient rectifier and low voltage schottky diode. This results in improved stability, improved ripple and lower temperatures. It’s also well within my soldering abilities!
The Exxos refurbishment kit, as it comesMitsumi SR98 PSU as it came, with replacement targets highlighted.Standard RectifierSchottky Diode
The fiddliest part is easily the rectifier as the new one is significantly larger and a different shape, but once it’s all done it looks something like the image below. A quick visual inspection underneath for bridged tracks and stray solder, maybe a quick clean with isopropanol and a toothbrush, and it’s ready to go.
The refurbished SR98 PSU, top sideRefurbished SR98 PSU, bottom side
The refurbished PSU is refitted carefully back into the case and reconnected to the low voltage header on the motherboard. Various parts of the PSU are mains live when turned on (danger of death!), so extreme care needs to be taken if the whole case isn’t reassembled. Also note that this PSU likes to be loaded – i.e. not to be run bare, so don’t turn it on without plugging something in (ideally a cheap bulb, rather than an expensive motherboard).
Using a multimeter I measured the voltage across the large 4700µF capacitor and trimmed VR201 down slightly to bring the voltage closer to 5.00V.
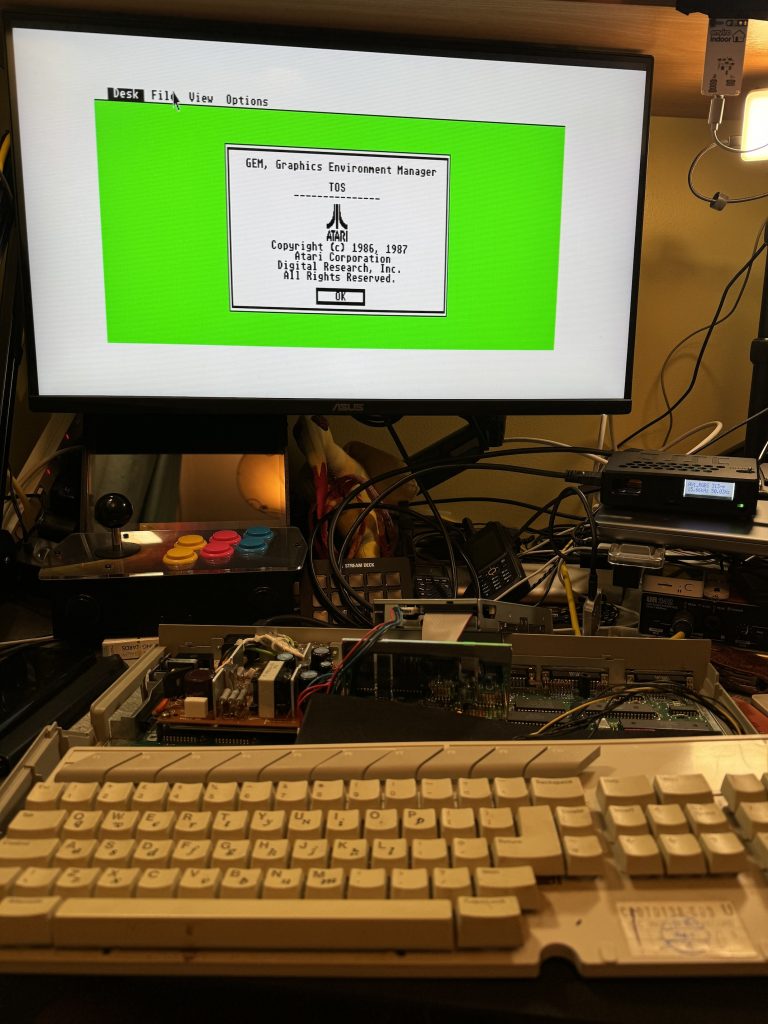
Now flipping the power switch results in a little green desktop and no magic smoke!
Little Green Desktop
This booted without a keyboard, mouse or floppy drive. I used an RGB SCART cable to an OSSC scan doubler (middle right), then HDMI to a regular modern monitor. The image in both low and medium resolutions is crisp and clear with very little hint of instability.
Next steps: cleaning the keyboard, retrobrighting the case, upgrading the TOS ROMS, fitting the 4MB RAM upgrade, Gotek and ultrasatan drives.
All the information I used for this PSU refurbishment was from the Exxos Forum.
Since I first played around with my first ADC on the BBC Micro in the early ’90s, I’ve always had a bit of a thing for data logging of one sort or another – when building data visualisations or just playing around with datasets it’s usually more fun working with data you’ve collected yourself.
So a few years ago I bought a little weather station to stick up in the garden, mostly for my wife, who’s the gardener, to keep an eye on the temperature, wind, humidity, etc. It has a remote sensor array in the garden running off a few AA batteries and transmitting wirelessly to a base station, with a display, which we keep in the kitchen. The base station also displays indoor temperature & pressure.
I discovered, more recently, that the sensor array transmits its data on 433MHz which is a license-free band for use by low power devices. At around the same time, I also discovered the cheap RTL-SDR repurposed DVB-T USB stick and eventually found my way over to the very convenient rtl_433 project.
Eventually, I wanted to try and build a datalogger for the weather station, but rather than periodically plugging the base station into something to offload the data it already captures, or leave something ugly plugged into the base station in the kitchen, I figured I’d configure a spare raspberry pi with rtl_433 and run it somewhere out of the way, so I duly went ahead and did that. It works really well and I’ve added a basic web UI which mimics the original base station display and combines it with data from elsewhere (like moon phases) and my intention is eventually to combine all sorts of other stuff like APT weather satellite imagery and maybe even sunspot activity for my other radio-based interests.
Even though the capture has been running permanently for at least a year now I’ve never really gone back to look at the data being logged, which was one of my original plans (temperature trend plots). Having a poke around the data this morning reminded me that actually there are lots of other things which broadcast on the same frequency and I wanted to share them here.
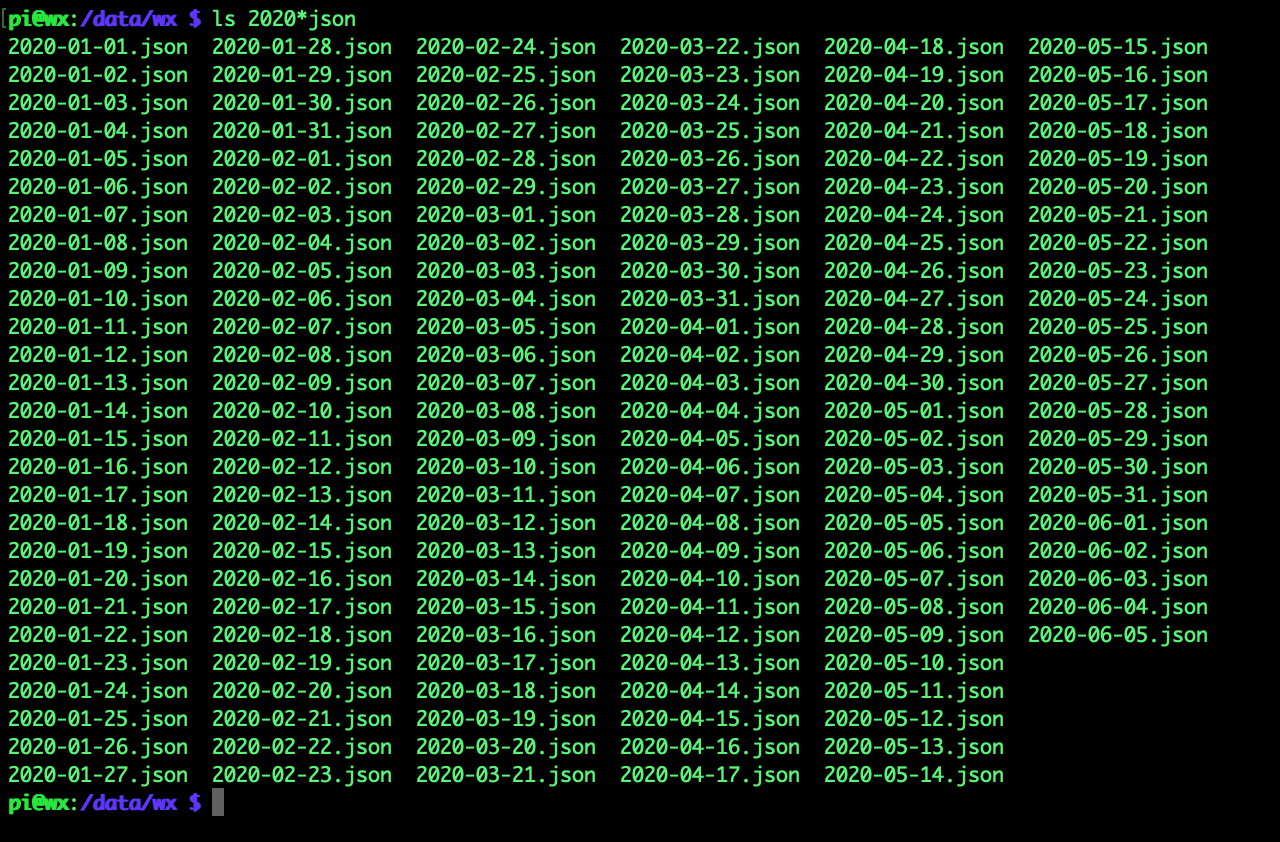
My logger logs to JSON format files by date, which makes it quite easy to munge the data with jq. The folder looks something like this:
The contents of the files is nicely formatted and mostly looks like this
Meaning I can batter my little raspberry pi and run a bit of jq over all the files:
That is to say: dump all of the 2020 JSON files, slurp them all into a big array in jq, group them into separate arrays by the “model” field, then transform those multiple arrays into just the name from the first element and a count of how many elements were in each array. Neat!
My poor little Pi didn’t like it very much. Each of those files has up to about 3000 records in and slurping the whole lot into memory leads to sad times.
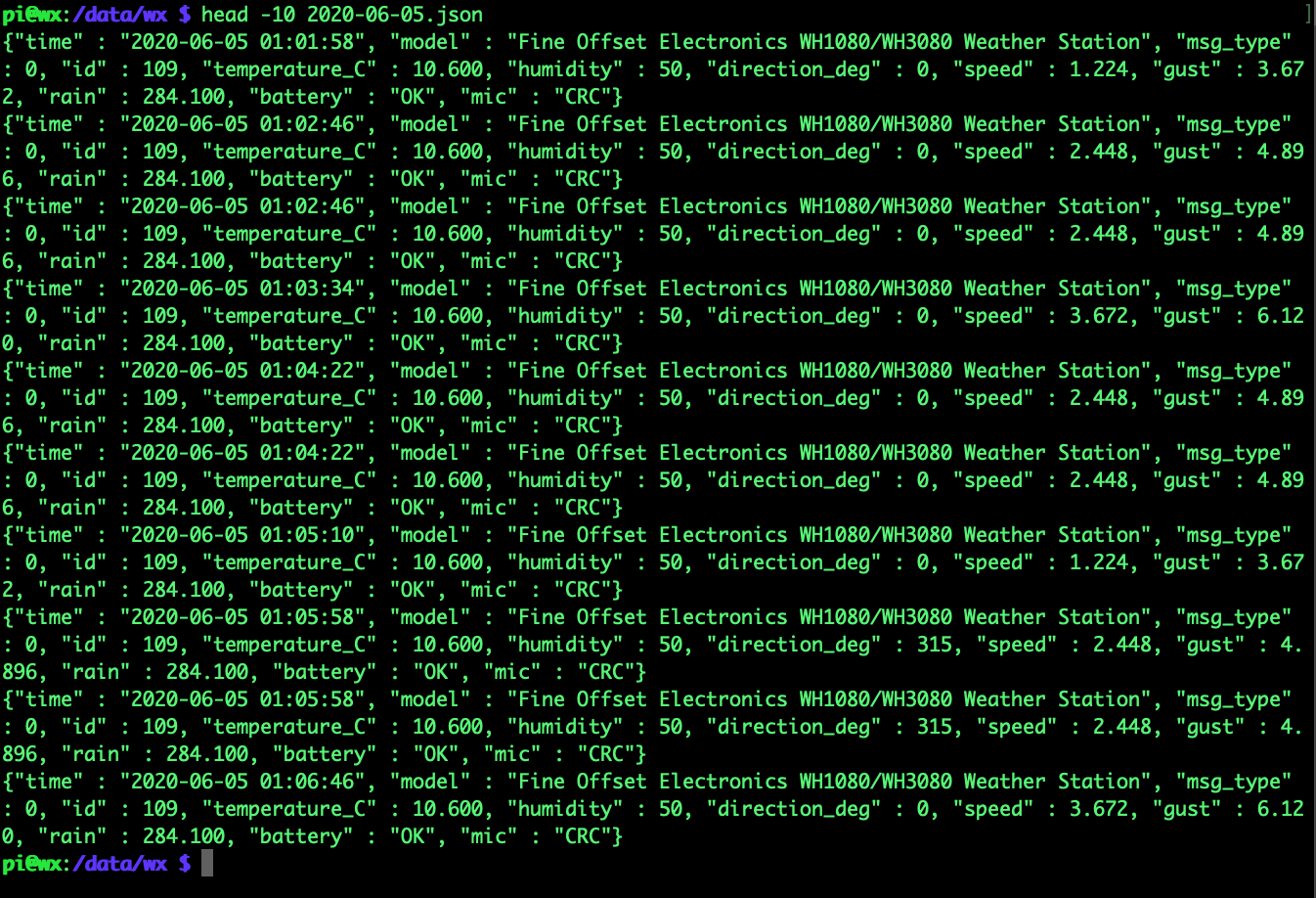
Ok, so running one of the files alone ends up with a clean result
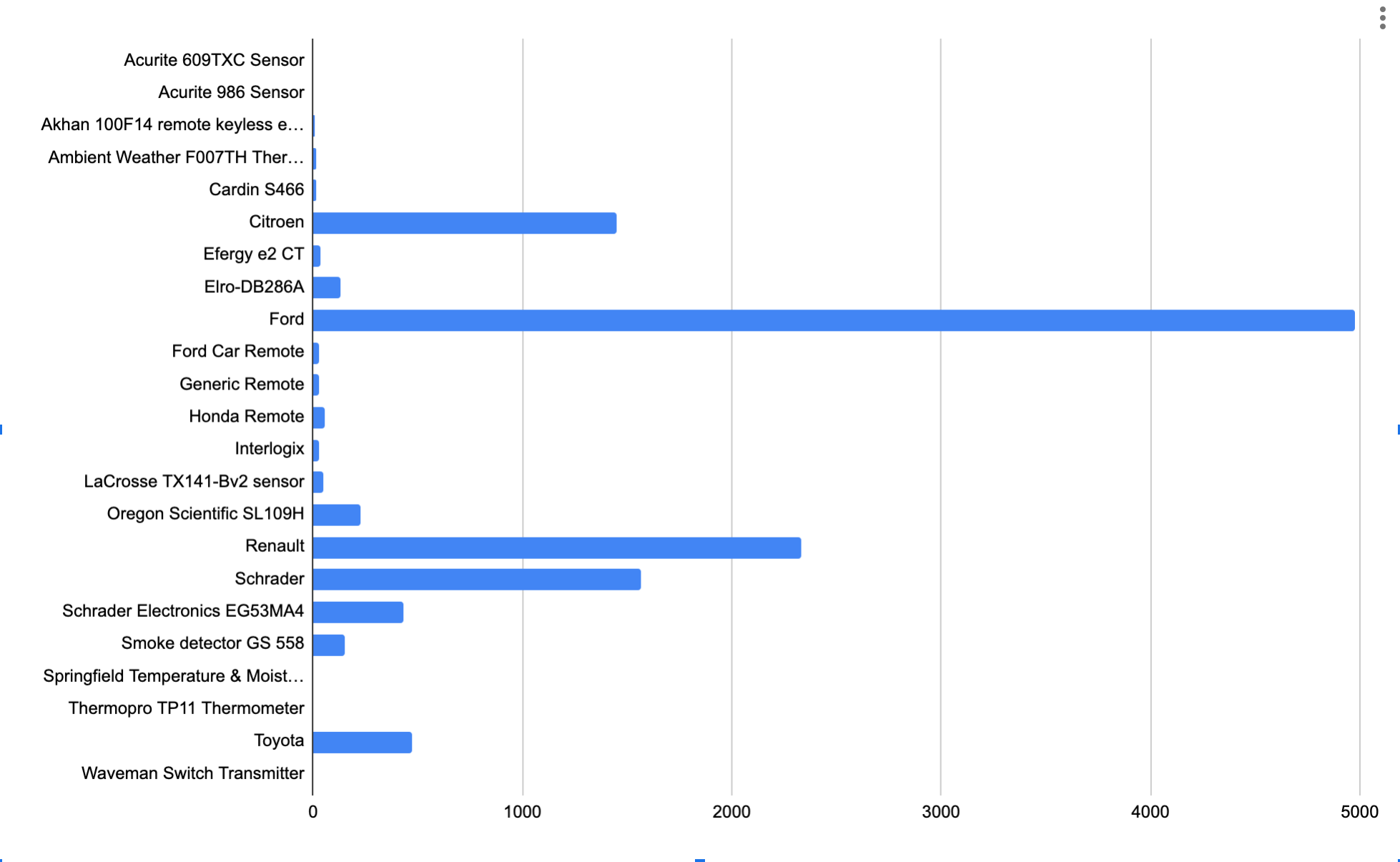
So mostly weather station data from (presumably!) my WH1080/WH3080 sensor array. The Oregon Scientific SL109H also looks like a weather station – I didn’t think my base station transmitted indoor temps, but I could be mistaken – will have to have a look. Someone else is also running a F007TH Hygrometer doing something similar, too. Citroen, Ford, Renault and Schrader are all tyre pressure sensors of neighbours and/or passing traffic. The Elro-DB286A is a neighbours wireless doorbell… that could be fun spoofing, and the GS558 is obviously a smoke detector, a lot less fun spoofing.
So, I can build tallies for each dated file like so:
for i in 2020*json; do
cat $i \
| jq --slurp 'group_by(.model)|map({model:.[0].model,count:length})|.[]';
done > /tmp/2020-tallies.json
Removing my weather station from the set, as it dwarfs everything else, the results look like this:
RTL433 Device type frequency in a rural neighbourhood
So aside from Ford having the most cars with tyre pressure monitors, it looks like there are a few other interesting devices to explore. Those car remotes don’t feel very secure to me, that’s for sure.
I’ve only just scratched the surface here, so if you’ve found anything interesting yourself with rtl_433, or want me to dig a bit deeper into some of the data I’ve captured here please let me know in the comments.
Do you, like me, develop desktop applications for MacOSX? Do you, like me, do it on Linux because it makes for a much cheaper and easier to manage gitlab CI/CD build farm? Do you still sign your apps using a MacOSX machine, or worse (yes, like me), not sign them at all, leaving ugly popups like the one below?
With the impending trustpocalypse next month a lot of third-party (non-app-store) apps for MacOSX are going to start having deeper trust issues than they’ve had previously, no doubt meaning more, uglier popups than that one, or worse, not being able to run at all.
I suspect this trust-tightening issue, whilst arguably a relatively good thing to do to in the war against malware, will adversely affect a huge number of open-source Mac applications where the developer/s wish to provide Mac support for their users but may not wish to pay the annual Apple Developer tax even though it’s still relatively light, or may not even own any Apple hardware (though who knows how they do their integration testing?). In-particular this is likely to affect very many applications built with Electron or NWJS, into which group this post falls.
Well, this week I’ve been looking into this issue for one of the apps I look after, and I’m pleased to say it’s at a stage where I’m comfortable writing something about it. The limitation is that you don’t sidestep paying the Apple Developer tax, as you do still need valid certs with the Apple trust root. But you can sidestep paying for more Apple hardware than you need, i.e. nothing needed in the build farm.
First I should say all of the directions I used came from a 2016 article, here. Thanks very much to Allin Cottrell.
Below is the (slightly-edited) script now forming part of the build pipeline for my app. Hopefully the comments make it fairly self-explanatory. Before you say so, yes I’ve been lazy and haven’t parameterised directory and package names yet.
#!/bin/bash
#########
# This is a nwjs (node) project so fish the version out of package.json
#
VERSION=$(jq -r .version package.json)
#########
# set up the private key for signing, if present
#
rm -f key.pem
if [ "$APPLE_PRIVATE_KEY" != "" ]; then
echo "$APPLE_PRIVATE_KEY" > key.pem
fi
#########
# temporary build folder/s for package construction
#
rm -rf build
mkdir build && cd build
mkdir -p flat/base.pkg flat/Resources/en.lproj
mkdir -p root/Applications;
#########
# stage the unsigned applicatio into the build folder
#
cp -pR "../dist/EPI2MEAgent/osx64/EPI2MEAgent.app" root/Applications/
#########
# fix a permissions issue which only manifests after following cpio stage
# nw.app seems to be built with owner-read only. no good when packaging as root
#
chmod go+r "root/Applications/EPI2MEAgent.app/Contents/Resources/app.nw"
#########
# pack the application payload
#
( cd root && find . | cpio -o --format odc --owner 0:80 | gzip -c ) > flat/base.pkg/Payload
#########
# calculate a few attributes
#
files=$(find root | wc -l)
bytes=$(du -b -s root | awk '{print $1}')
kbytes=$(( $bytes / 1000 ))
#########
# template the Installer PackageInfo
#
cat <<EOT > flat/base.pkg/PackageInfo
<pkg-info format-version="2" identifier="com.metrichor.agent.base.pkg" version="$VERSION" install-location="/" auth="root">
<payload installKBytes="$kbytes" numberOfFiles="$files"/>
<scripts>
<postinstall file="./postinstall"/>
</scripts>
<bundle-version>
<bundle id="com.metrichor.agent" CFBundleIdentifier="com.nw-builder.epimeagent" path="./Applications/EPI2MEAgent.app" CFBundleVersion="$VERSION"/>
</bundle-version>
</pkg-info>
EOT
#########
# configure the optional post-install script with a popup dialog
#
mkdir -p scripts
cat <<EOT > scripts/postinstall
#!/bin/bash
osascript -e 'tell app "Finder" to activate'
osascript -e 'tell app "Finder" to display dialog "To get the most of EPI2ME please also explore the Nanopore Community https://community.nanoporetech.com/ ."'
EOT
chmod +x scripts/postinstall
#########
# pack the postinstall payload
#
( cd scripts && find . | cpio -o --format odc --owner 0:80 | gzip -c ) > flat/base.pkg/Scripts
mkbom -u 0 -g 80 root flat/base.pkg/Bom
#########
# Template the flat-package Distribution file together with a MacOS version check
#
cat <<EOT > flat/Distribution
<?xml version="1.0" encoding="utf-8"?>
<installer-script minSpecVersion="1.000000" authoringTool="com.apple.PackageMaker" authoringToolVersion="3.0.3" authoringToolBuild="174">
<title>EPI2MEAgent $VERSION</title>
<options customize="never" allow-external-scripts="no"/>
<domains enable_anywhere="true"/>
<installation-check script="pm_install_check();"/>
<script>
function pm_install_check() {
if(!(system.compareVersions(system.version.ProductVersion,'10.12') >= 0)) {
my.result.title = 'Failure';
my.result.message = 'You need at least Mac OS X 10.12 to install EPI2MEAgent.';
my.result.type = 'Fatal';
return false;
}
return true;
}
</script>
<choices-outline>
<line choice="choice1"/>
</choices-outline>
<choice id="choice1" title="base">
<pkg-ref id="com.metrichor.agent.base.pkg"/>
</choice>
<pkg-ref id="com.metrichor.agent.base.pkg" installKBytes="$kbytes" version="$VERSION" auth="Root">#base.pkg</pkg-ref>
</installer-script>
EOT
#########
# pack the Installer
#
( cd flat && xar --compression none -cf "../EPI2MEAgent $VERSION Installer.pkg" * )
#########
# check if we have a key for signing
#
if [ ! -f ../key.pem ]; then
echo "not signing"
exit
fi
#########
# calculate attribute
: | openssl dgst -sign ../key.pem -binary | wc -c > siglen.txt
#########
# xar the Installer package
#
xar --sign -f "EPI2MEAgent $VERSION Installer.pkg" \
--digestinfo-to-sign digestinfo.dat --sig-size $(cat siglen.txt) \
--cert-loc ../dist/tools/mac/certs/cert00 --cert-loc ../dist/tools/mac/certs/cert01 --cert-loc ../dist/tools/mac/certs/cert02
#########
# construct the signature
#
openssl rsautl -sign -inkey ../key.pem -in digestinfo.dat \
-out signature.dat
#########
# add the signature to the installer
#
xar --inject-sig signature.dat -f "EPI2MEAgent $VERSION Installer.pkg"
#########
# clean up
#
rm -f signature.dat digestinfo.dat siglen.txt key.pem
With all that you still need a few assets. I built and published (internally) corresponding debs for xar v1.6.1 and bomutils 0.2. You might want to compile & install those from source – they’re pretty straightforward builds.
Next, you need a signing identity. I used XCode (Preferences => Accounts => Apple ID => Manage Certificates) to add a new Mac Installer Distribution certificate. Then used that to sign my .app once on MacOS in order to fish out the Apple cert chain (there are probably better ways to do this)
I set this up the contents of key.pem as a gitlab CI/CD Environment Variable APPLE_PRIVATE_KEY so it’s never committed to the project source tree.
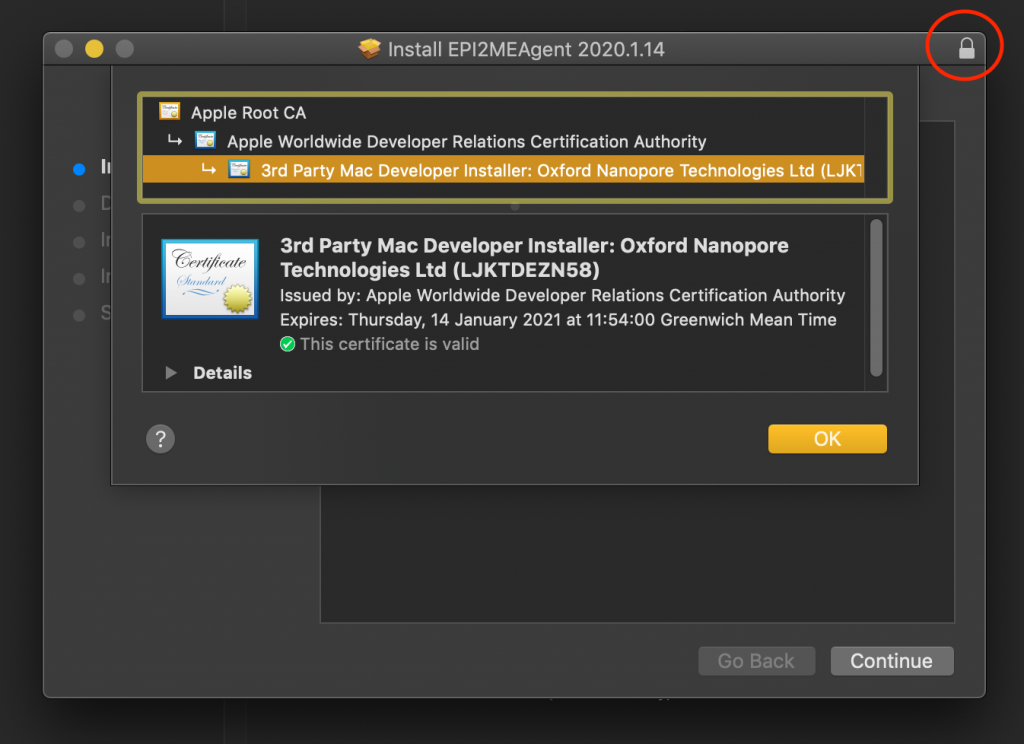
Once all that’s in place it should be possible to run the script (paths-permitting, obviously yours will be different) and end up with an installer looking something like this. Look for the closed padlock in the top-right, and the fully validated chain of certificate trust.
In conclusion, the cross-platform application nwjs builds (Mac, Windows, Linux) all run using nw-builder on ubuntu:18.04, and the Mac (and Windows, using osslsigncode, maybe more on that later) also all run on ubuntu:18.04. Meaning one docker image for the Linux-based Gitlab CI/CD build farm. Nice!
At work, I have a CLI tool I’ve been working on. It talks to the web and is used by customers all over the planet, some of them on networks with tighter restrictions than my own. Often those customers have an HTTP proxy of some sort and that means the CLI application needs to negotiate with it differently than it would directly with a web server.
So I need to test it somehow with a proxy environment. Installing a proxy service like Squid doesn’t sound like too big a deal but it needs to run in several configurations, at a very minimum these three:
no-proxy
authenticating HTTP proxy
non-authenticating HTTP proxy
I’m going to ignore HTTPS proxy for now as it’s not actually a common configuration for customers but I reckon it’s possible to do with mkcert or LetsEncrypt without too much work.
There are two other useful pieces of information to cover, firstly I use GitLab-CI to run the CI/CD test stages for the three proxy configurations in parallel. Secondly, and this is important, I must make sure that, once the test Squid proxy service is running, the web requests in the test only pass through the proxy and do not leak out of the GitLab runner. I can do this by using a really neat Linux feature called IP namespaces.
IP namespaces allow me to set up different network environments on the same machine, similar to IP subnets or AWS security groups. Then I can launch specific processes in those namespaces and network access from those processes will be limited by the configuration of the network namespace. That is to say, the Squid proxy can have full access but the test process can only talk to the proxy. Cool, right?
The GitLab CI/CD YAML looks like this (edited to protect the innocent)
.network_ns: &network_ns | ip netns add $namespace ip link add v-eth1 type veth peer name v-peer1 ip link set v-peer1 netns $namespace ip addr add 192.168.254.1/30 dev v-eth1 ip link set v-eth1 up ip netns exec $namespace ip addr add 192.168.254.2/30 dev v-peer1 ip netns exec $namespace ip link set v-peer1 up ip netns exec $namespace ip link set lo up ip netns exec $namespace ip route add default via 192.168.254.1
So there are five blocks here, with three stages and two common script blocks. The first common script block installs iproute2 which gives us the ip command.
The second script block is where the magic happens. It configures a virtual, routed subnet in the parameterised $namespace.
Following that we have the three test stages corresponding to the three proxy (or not) configurations I listed earlier. Two of them install Squid, one of those creates a test user for authenticating with the proxy. They all run the test script, which in this case is test/end2end/cli. When those three configs are modularised and out like this with the common net namespace script as well it provides a good deal of clarity to the test maintainer. I like it a lot.
So then the last remaining things are the respective squid configurations: proxyauth and proxynoauth. There’s a little bit more junk in these than there needs to be as they’re taken from the stock examples, but they look something like this:
http_access allow authenticated http_access deny all http_port 3128
And there you have it – network-restricted proxy testing with different proxy configurations. It’s the first time I’ve used ip net ns without being wrapped up in Docker, LXC, containerd or some other libvirt thing, but the feeling of power from my new-found network-god skills is quite something :)
Be aware that you might need to choose different subnet ranges if your regular LAN conflicts. Please let me know in the comments if you find this useful or if you had to modify things to work in your environment.